

第一步,檢查索引
在針對網頁索引進行優化之前,第一步就是先檢查網頁是否真的沒有 Google 收錄,可以使用兩個工具來檢查:
- Google Search Console-使用 GSC 的網址審查看網頁索引狀態,若出現「網頁已編入索引」則表示網頁已被 Google 收錄;反之,若出現「網頁未編入索引」,則表示該網頁尚未被 Google 收錄。
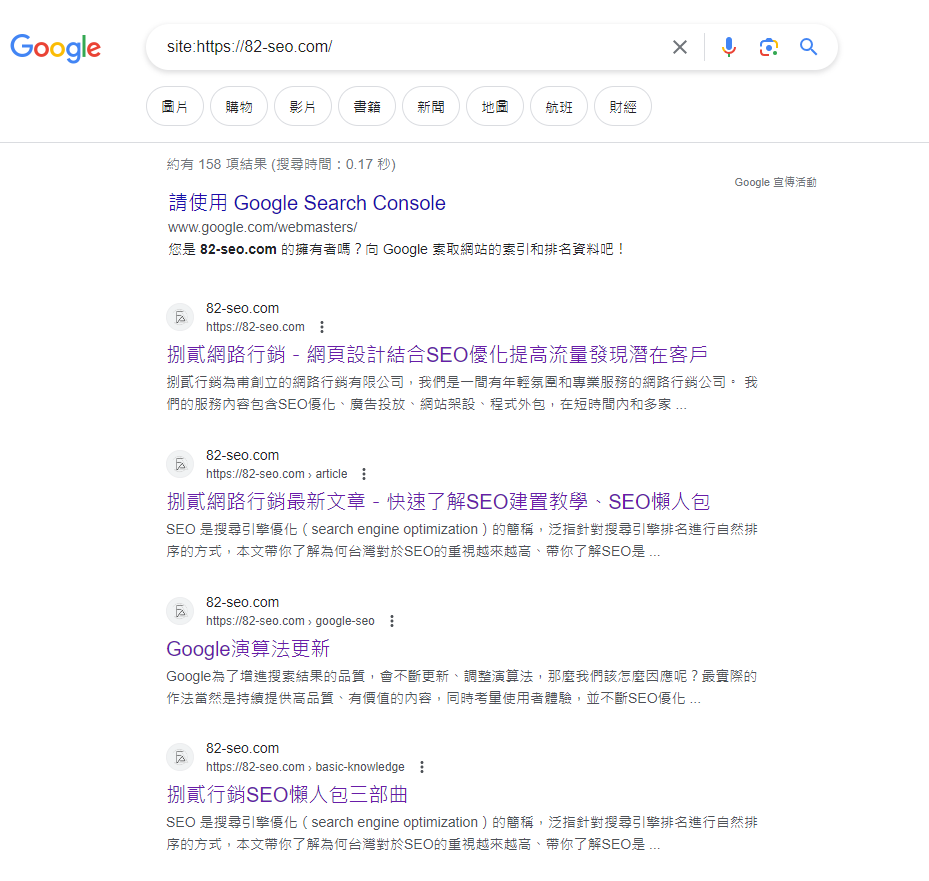
- 「site:」指令-在 Google 搜尋欄中使用 site: 網址,例如「site:https://82-seo.com/」,可以看到已被編入索引的網頁,不過「site:」指令有可能無法完整顯示所有被索引的網頁,所以使用 GSC 還是比較準確。
網站未被 Google 索引的 10 個原因
1、頁面沒有建立內部連結
Google 的搜尋引擎爬蟲在抓取網站時,透過內部連結來發現新網頁並為其建立索引,所以建立內部連結對搜尋引擎索引網頁起著至關重要的作用。
如果網站缺乏內部連結,搜尋引擎爬蟲可能難以發現其所有頁面,這可能會導致某些頁面未被索引。
2、沒有提交 Sitemap
Sitemap 有助於確保每個頁面都被 Google Search Console 抓取並編入索引。
當網頁沒有提交 Sitemap 不代表不會被 Google 索引,只是可能會比較慢才被 Google 爬蟲發現,但網頁提交 Sitemap 後可以幫助爬蟲更容易地發現頁面並且為其建立索引。
3、網站載入速度過慢
當 Googlebot 抓取網站以為其內容編制索引時,它的預算和時間是有限的。
當網站很大並且加載緩慢時,對爬蟲進行檢索帶來不便, Googlebot 就可能無法在給定的時間限制內索引所有頁面。
而且對於加載過慢的網站,Google 不太希望它們出現在搜尋結果頁面的前端,所以網站不但有可能無法索引也有可能不會獲得很好的 SEO 排名。
4、Robots.txt 或 Noindex 設定錯誤
Robots.txt 誤用了「Disallow:」路徑阻止爬蟲爬行網頁,若爬蟲無法檢索網頁,網頁就根本無法被收錄。
而 Noindex 元標籤就是指示 Google 不要為該頁面建立索引,表示該頁面不會出現在搜尋結果中。
延伸閱讀【Robots.txt 是什麼以及它如何優化 SEO?跟 Noindex 又有什麼區別呢?】
5、不正確的 Canonical URL
當網站有多個顯示相似或重複內容的 URL 時,應使用 Canonical URL。
但是,如果沒有確切地告訴 Google 您希望搜尋引擎將哪個 URL 編入索引,Google 會自行選擇,這可能會導致錯誤的版本被編入索引。
6、網站太新
有時候網站其實沒有任何問題,只是剛上線,Google 需要時間來抓取網頁並為其建立索引,Google 抓取網站所需的時間差異很大,從幾個小時到幾週不等。
這時除了等待之外,最好的解決方法就是不斷添加和維護網站上的內容。這樣當 Google 將您的網站編入索引時,您就已經為網站建立了許多可靠的相關來源,這對於獲得更高的 SEO 排名並與受眾建立信任非常重要。
7、網站結構不佳
在建立索引時,Google 會優先考慮提供良好使用者體驗的網站,因為 Google 希望為使用者的查詢提供有用且最相關的資源。
這意味著機器人可能會戶略用戶難以瀏覽的網站,糟糕的網站結構也會阻礙 Google 抓取網頁的能力。
8、網頁不適合行動裝置
超過一半的用戶上網是透過行動裝置進行的,所以 Google 在抓取網站時會優先考慮行動裝置友善性。
若網站未針對行動裝置進行優化,Google 可能不會將其編入索引。
9、低品質的內容
Google 希望能向用戶提供獨一無二、準確且最新的搜尋結果。
因此若網頁內容過少、抄襲或使用關鍵字堆砌,可能會降低 Google 將您的網站編入索引的機會。
10、重定向循環
重定向循環將使 Google 無法正確地索引頁面,因為機器人會陷入這些循環中並且無法繼續抓取網站。
重定向循環是什麼?
當一個 URL 重新導向到另一個 URL,而另一個 URL 又重新導回到最初的 URL 時,就會發生閉合的重定向鏈,從而導致重定向的無限循環,用戶和搜尋引擎將永遠不會看到目標頁面。





